Data scientists are in a unique area with machine learning, statistical analysis in addition to data mining. This mix can help uncover new information from data already in use through algorithms and statistical analysis. In data science, a variety of machine learning algorithms is utilized to solve various types of issues, as a single algorithm might not be the ideal choice for every use case. Data scientists often employ different kinds of machine learning algorithms.
This article presents the list of machine-learning methods that researchers commonly use to get real-time and useful outcomes.
1. Logistic and Linear Regression
Linear Regression
Regression analysis is a method that estimates the relationships to dependent variables. Linear Regression is a method for solving regression issues, while logistic Regression is used to solve classification issues. Linear Regression refers to an estimating technique that has been used for over 200 years.
Let’s suppose that you have a variable y linearly dependent on the variable x. Regression analysis can be described as formulating the constants a and B in the equation y = ax and b. These constants represent how linearly related variables both x and y.
Linear Regression identifies relationships between one or several predictive variables (s)and an outcome factor. Linear Regression is an extremely popular machine learning technique for that novice to data science. Students are required to calculate the characteristics of their training datasets.
The Swedish Auto Insurance Dataset on Kaggle is a basic case study using linear regression analysis to comprehend the connections between different data sets. The study predicts the total amount paid on all insurance claims considering the total number of claims.
Logistic Regression
Logistic Regression is a statistical method of creating machine learning models in which each dependent variable has a dichotomous, i.e. or binary. The method is utilized to explain data and the relationship that exists between one dependent variable and one or several independent variables. Coursera’s use for Logistic Regression to forecast the value of homes based on their attributes is an excellent study to understand the process.
Also Read: What All Are The Best Open-Source Data Science Projects?
2. Decision Trees and Random Forests
A decision tree is the arrangement of data into an arranged tree. Data is separated at every node in the tree structure into various branches. The data separation occurs according to the value of the attributes on the nodes. However, the decision trees are susceptible to high variability.
In many machine-learning algorithms, with examples, you’ll notice large variances, making decisions tree outcomes insufficient concerning the particular training data utilized. You can decrease variance by creating several models with highly correlated trees using the training data you have used.
Bagging is the term used to describe the process and can help reduce making a mistake in your choice trees. Random Forest is an extended version of bagging. Apart from creating trees from various training data samples, the machine learning algorithm blocks the characteristics that could be utilized to construct the trees. Therefore, each decision tree has to be distinct.
The Institute of Physics recently published an intriguing study that used random forests and decision trees to determine the likelihood of loan default. The machine learning algorithms they developed with examples can assist banks in picking the right people from a list of potential loan applicants.
Researchers used decision trees and random forests. Researchers utilized decision trees and random forests to determine the risk of any possible borrower (from the list of potential candidates). They utilized both machine learning algorithms and the Random Forest algorithm on the same data. Researchers discovered that the Random Forest algorithm provided more precise results than that of the Decision Tree algorithm.
Case study: Random Forest in Action: Predicting Climate Change and Forced Displacement
3. Gradient Boosting Machines
Gradient boosting devices like XGBoost, LightGBM, and CatBoost is the top machine learning algorithms to train with tabular datasets. XGBoost is simpler to work with since it is transparent, permits the simple plotting of trees and doesn’t have any integral categorical feature that encodes.
Researchers at the Center for Applied Research in Remote Sensing and GIS (CARGIS) in Vietnam recently utilized three powerful boosting machines (XGBoost, LightGBM, and Catboost) when combined with a Convolutional Neural Network (CNN) to classify the land cover.
The study proved that the combination of CNN-based gradient boosting machine learning algorithms and image analysis based on objects could result in an accurate method of study of landcover.
The Real World Course (Including the XGBoost): Detecting Heart Disease using Ensemble Techniques for Machine Learning
4. Convolutional Neural Networks (CNN)
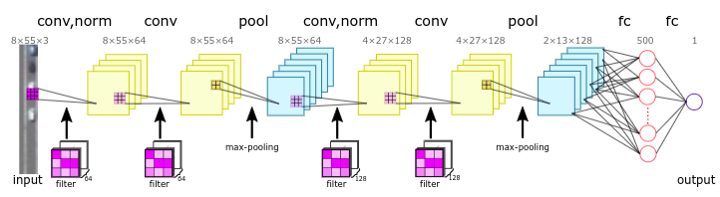
CNN includes various algorithms for machine learning that classify images into categorizing classes. The various layers of CNN remove image features from the data set. Gradually, they begin to categorize the images.
Original Network Structure derived from Traffic density estimation technique derived by using satellite images of small size for regular remote sensing of car traffic.
CNN’s in Action Save lives on Roads
Omdena recently published a case study in which CNN’s boosted road security. Researchers utilized pre-trained CNNs to classify and count the vehicles that travel on the road. The algorithms also looked at the flow of traffic and satellite images to develop safer traffic flow guidelines. Find out further below.
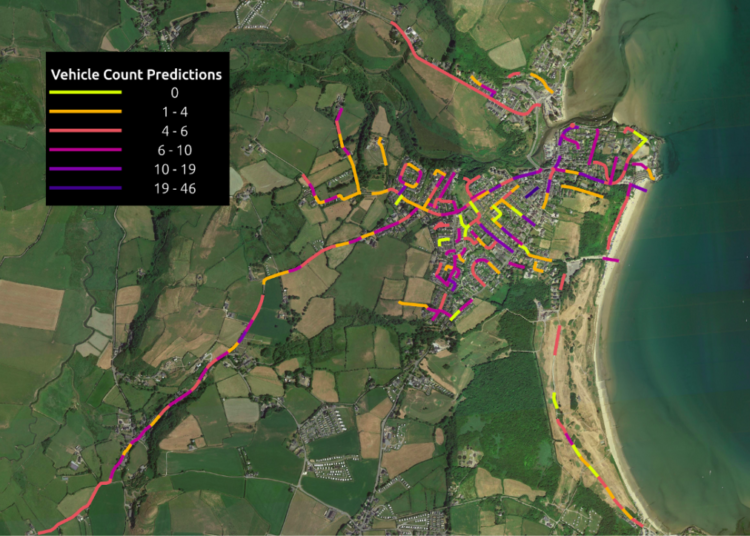
Visualization of the vehicle count predictions in the sample area. Source: Omdena
5. Bayesian Methodologies
Naive Bayes classifiers are a set of classification algorithms based upon the Bayes Theorem. The Naive Bayes classification method is allocated to the element in an array with the highest probability based on Bayes Theorem.
- Assume that the two are both probabilistic instances.
- Let the probability P (A) Be the likelihood of A being real.
- P(AB) is the term used to describe the probability that A is contingent on being true if B is true.
Then, as per Bayes theorem:
P (A|B) = (P (B|A) x P (A)) /P (B)
Is the machine learning algorithm list becoming unclear? Don’t fret. BayesiaLab has an easy, real-life case study that will help you understand Bayesian networks and methods. The case studies show that Bayesian networks are used to create a framework.
Bayesian methods allow researchers to design a faster and cheaper option to conduct market research. You can use this Bayesian market Simulator to run market share simulations directly on your computer.
6. Dense Neural Networks
Neurobiology has been the inspiration behind Deep Neural Networks (DNNs). These are Artificial Neural Networks (ANN) with additional layers between the input and output layers. Deep is the term used to describe more complicated tasks related to the number of units or layers in each layer. DNNs fall into three types. They are classified into three categories.
- Convolutional Neural Networks (CNN)
- Recurrent Neural Networks (RNN)
- Multilayer Perceptrons (MLPs)
Multilayer Perceptron (MLP) models are the simplest DNN composed of a set of connected layers. In a fascinating investigation from Iran, researchers calculated the volume of clay within a local reservoir to use six different types of good logs by using MLP-based networks to model results.
7. Recurrent Neural Networks
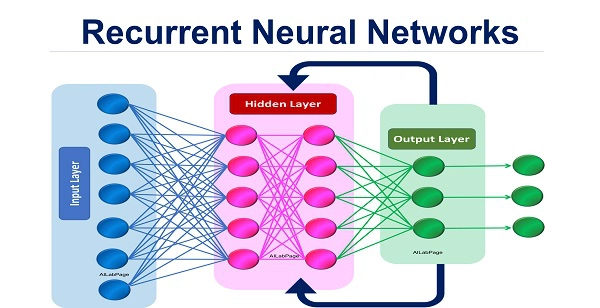
Recurrent Neural Networks
RNNs are a type of ANN that also utilize the concept of sequential data feeding. They are a form of machine learning algorithm that can help solve time-series issues of serial input data. They offer:
- Machine Translations
- Speech Recognition
- Language Modelling
- Text Generation
- Video Tagging
- Generate Images with Descriptions
Omdena’s case study of using RNNs to predict Sudden Cardiac Arrest (SCAs) using patients’ vitals and static information can be helpful.
You can find the details regarding “RNNs in Action Predicting Cardiac Arrest” here.
8. Transformer Networks
Transformer networks refer to neural networks that use Attention Layers as the main components. A relatively modern machine learning technique has revolutionized the area of Natural Language Processing. The most well-known transformer networks that have been trained are –
- BERT
- GPT-2
- XLNet
- MegatronLM
- Turing-NLG
- GPT-3
Here’s A study using GPT-3 to carry out custom tasks in the language. The model of the language transformer required minimal training data to improve its accuracy. Electronic Health Records (EHRs).
9. Generative Adversarial Networks
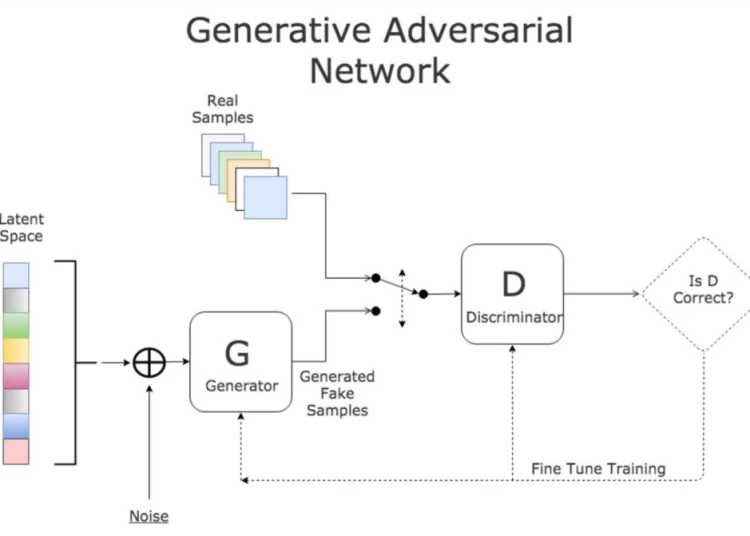
Generative Adversarial Networks
Generative Adversarial Networks (GANs) are neural networks composed of the generator and the discriminator. They compete with each other against each other. The generator creates data sets, while the discriminator can validate the data set. AI Startup Spaceport recently announced a partnership with Omdena to create deep-learning Generative Adversarial Networks to identify trees.
GANs for Good: Detecting Wildfires
The model was developed to stop forest fires. Omdena’s team used GANs to carry out labels for data and data augmenting. The final result was that Omdena’s team found that the Deep U-Net algorithm could recognize trees from massive data sets.
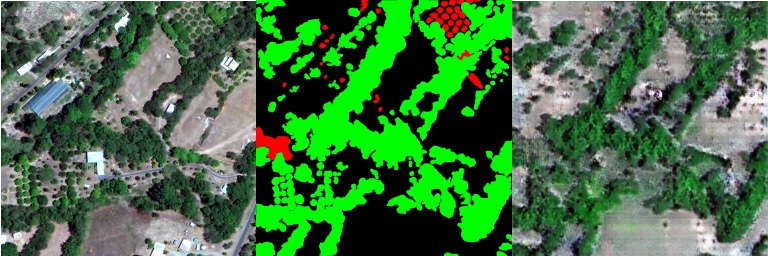
Generating Images with Just Noise using GANs to Detect Trees and Wildfires
10. Evolutionary Methodologies
The last on the list of machine learning algorithms are a class of evolutionary optimization algorithms referred to in “Evolutionary Methods” or EAs. Some of the most well-known methods in the field of evolutionary computation include:
- Genetic algorithmic algorithms (GA)
- Genetic Programming (GP)
- Differential Evolution (DE)
- The Evolution Strategy (ES)
- The Evolutionary Programming (EP)
Here’s An instance study that illustrates how EAs improve the warehouse’s storage process. The model created at Zilina University University of Zilina assists in optimizing the workload for warehouse employees.