
Machine Learning is a type of artificial intelligence that focuses on creating systems that learn from past data recognize patterns, and make logical choices without human involvement. It is a method of data analysis that automates the construction of models that are analytical by making use of data that includes a variety of types of digital data, including numbers words, clicks, words, and even images.
What is Machine learning?
Machine learning software learns from input data and constantly improves the quality of outputs by using automated optimization techniques. The accuracy of a machine-learning model is determined by two key factors:
1. Quality of data input. A common phrase when it comes to developing algorithmic models for machine learning can be “garbage in, garbage out”. The phrase means that when you input bad quality or messy data, the model’s output is likely to be in error.
2. The decision to choose the model is the model itself. In machine learning, there are many algorithms that data scientists can pick from, each with particular applications. It is crucial to select the right algorithm for every application. Neuronal networks can be described as an algorithm that is gaining a lot of buzz due to the high precision and flexibility they could offer. For small amounts of data, choosing an easier model is likely to be more effective.
The more accurate the machine-learning model is, the better it is able to detect patterns and characteristics in the data. This, in turn, means that the more accurate its conclusions and predictions will be.
Why is Machine Learning Important?
What is the purpose of using machine learning? Machine learning is gaining importance due to the ever-growing quantities and varieties of data, the accessibility and affordability of computing power, and the accessibility of high-speed Internet. Digital transformation makes it possible to develop quickly and easily models that are able to quickly and efficiently analyze massive and complex data sets.
There are many applications that machine learning can be used in order to reduce costs, reduce risks and improve overall satisfaction, including providing recommendations for products and services and detecting cybersecurity breaches, and even enabling self-driving vehicles. With increased access to information and computing capabilities, machine learning is becoming widespread each day and will soon be integrated into a variety of aspects of daily life.
Also Read: Top 10 Machine Learning Algorithms for Data Scientists
How Does Machine Learning Work?
There are four steps to take when creating the machine learning model.
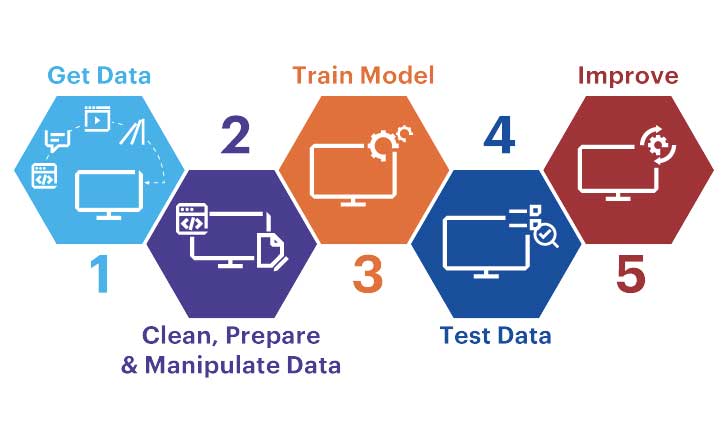
1. Choose and Prepare a Training Data Set
Training data refers to information that is representative of data that the machine learning software will use to adjust the parameters of the model. The training data may be labeled. This means that it is tagged to identify classes or expected values that the machine learning model must be able to predict. Some training data could be unlabeled and the model will need to identify the details and create clusters on its own.
To be labeled, the data must be split into a training subset as well as a testing subset. The first can be utilized to build the model, and the latter is used to assess the performance of the model as well as find ways to enhance it.
2. Select an Algorithm to Apply to the Training Data Set in machine learning
The type of machine-learning algorithm you choose will mostly depend on several aspects:
- If the case of use is the prediction of a value, or classification using labels on training data, or whether the application is the reduction of dimensionality or clustering that employs training data that is not labeled
- How much information is contained and included in the training set?
- It is the character of the issue that the model aims to solve
For classification or prediction scenarios, it is common to employ regression algorithms like simple least square regression as well as logistic regression. For data that isn’t labeled You are likely to use clustering algorithms, such as K-means or the closest neighbor. Certain algorithms, such as neural networks are programmed to function with predictions and clustering.
3. Train the Algorithm to Build the Model
The process of training the algorithm involves changing the parameters and variables of the model to better predict the most appropriate outcomes. Learning an algorithm for machine learning is typically iterative and employs different optimization strategies dependent on the model chosen. These methods of optimization don’t require any human intervention which is a major part of the effectiveness that machine learning. The machine is able to learn from the information you provide it, with no particular direction from you as the user.
4. Use and Improve the Model
The final step is feeding fresh data into the model in hopes to improve its efficiency and accuracy as time passes. The place where the new data will come from is contingent upon the type of issue to be resolved. For example, the machine learning model for autonomous cars will gather real-world information about roads, road conditions, and objects, as well as traffic laws.
How can I build better ML models more quickly?
Transform ML code into a high-end ML solution for production. Engine for ML Data-driven business. Dependable ML lifecycle management, and real-time execution. data-driven business and operational decision-making. Optimize and manage the whole ML lifecycle from experiment tracking to monitoring the model’s production.
Why is a framework so important?
A framework for machine learning is crucial for a variety of reasons.

- It establishes a standard process to guide the analysis of data and modeling
- It helps others understand how the problem was solved and fix projects that were not as successful.
- It requires one to be more thoughtful about the problem they’re trying to resolve. This can include things like the variables that will be determined, what the limits are, and the potential issues that may occur.
- It encourages people to do more research in their work, thereby increasing the credibility of their results and/or the final result.
With these ideas to be considered, let’s look at the basis!
Also Read: YouTube Uses Artificial Intelligence and Machine Learning
The Machine Learning Life Cycle Management
Are you looking for a project idea but aren’t sure where to begin? Maybe you’ve got data and you’re looking to develop a machine learning model, but aren’t certain of how to go about the task.
In this post, I’ll be talking about the conceptual framework you can employ to tackle every machine learning-related project. The framework is based on a conceptual framework and is identical to all the variants that are part of this machine learning cycle that you’ll find on the internet.
Although there are numerous variations of the machine-learning life cycle, they all are based on four basic stages that include planning, data collection modeling, production, and planning.
1. Planning
Before beginning the process of starting any machine learning endeavor there are a lot of items you’ll need to think about. In this instance”plan” covers a variety of things to do. When you complete this step you’ll have a better knowledge of the problem you’re trying to solve and make an informed decision about whether to take the next step or not.
The planning process includes the following tasks:
- The problem you’re trying to resolve. It might appear to be a simple process, but you’ll be amazed at the number of times people attempt to find an answer to a problem that doesn’t exist, or that’s not necessarily a problem.
- The business goal that you wish to attain to resolve the issue. The objective should be quantifiable. “Being the best company in the world” isn’t an objective that can be measured, however something like “Decrease fraudulent transactions” is.
- Find the variable of interest in the event that it is applicable, and any possible features variables that could be worth taking a take a look at. For instance, if your goal is to reduce the amount that is fraudulent, you’ll likely require labeled data of fraud and legitimate transactions. There are other features you may require like the date that the transaction took place, the account’s ID, as well as the ID of the user.
- Take into consideration all limitations, uncertainties, and potential risks. This could include the following, but are not limited to things such as resources limitations (lack of capital employees, time, or capital) and limits to infrastructure (eg. insufficient computing power to build a sophisticated neural network), and limitations on data (unstructured data, absence of data points, inaccessible data, etc.)
- Establish your success metrics. How can you tell if you’ve succeeded in achieving your goal? Does it count as a success in the event that your machine-learning model is accurate to 90? How about the other 85%? Is accuracy the most appropriate measure for your business’s needs?
If you’ve completed this step and feel comfortable with the task, then you can proceed to the next phase.
2. Data
This process is focused on collecting information, analyzing, and cleansing your information. In particular, it involves the following activities:
- Combine and store the information you’ve specified during the planning phase. If you’re collecting data from different sources, you’ll need to combine the data into one table.
- Wrangle your data. This means cleaning and changing your data so that it is better suited to be used in EDA or modeling. The things you’ll need to examine are duplicate data, missing values as well as noise.
- Do exploratory data analysis (EDA). Also called data exploration, this is essential to help you gain a better understanding of your data.
3. Machine Learning Modeling
Once you have your data ready to go, you are able to begin to build your model. There are three major steps that you must follow:
- Choose your model The model you pick ultimately will depend on the specific problem you’re trying to solve. For instance, if it’s the case of a classification or regression problem will require different ways of modeling.
- Training your models Once you’ve decided on your model and separated your data, you are able to develop your model by using the data you used to train it.
- Test your model Once you are satisfied the model you’ve created is completed You can test your model using test data that you have gathered in accordance with the established success metrics you’ve selected.
4. Production
The final step is to produce your model. This process isn’t spoken about in online courses, but it is crucial for businesses in particular. If you don’t take the step you take, you will not gain the maximum value of the models you create. There are two major aspects to take into consideration in this process:
- Machine Learning Model Deployment: Deploying the machine-learning model also known as model deployment means incorporating an existing machine learning model, and incorporate model into an established production environment in which it will receive inputs and produce an output.
- Monitoring Model: Model Monitoring is an operational phase in the lifecycle of machine learning which occurs following the model deployment and involves monitoring your model’s model for crashes, errors, and latency. But most importantly, to make sure the model’s operating at the desired quality of performance.
That’s the general arrangement of the life cycle of machine learning.
Importance Of Machine Learning Life Cycle Management
It is crucial as it defines the function of each individual in the company involved with respect to data science projects which range from the business side to engineering.
It covers each project from its inception to its completion and provides a broad overview of how a complete data science initiative should be structured to yield tangible, real-world business value.
Failure to execute accurately any of these steps can lead to models that are of no value in the real world or give misleading and inaccurate insights.
Although there are a variety of established technologies that can help with each stage of this process. There aren’t many solutions that can tie the various components into one cohesive ML platform.
To support the life cycle of ML models, you need to be able to manage the diverse ML-related artifacts, as well as their associated data, and automate the deployment. A lifecycle management platform is designed to support this goal and should be utilized to store, version visualization (including associations), and distribute the artifacts.
In recent times there has been a rise in enterprise solutions that operate ML activities to manage ML life cycle management.
For instance, Israel-based Qwak is a company that possesses a deep understanding of teams working in the data science domain to manage ML throughout the enterprise and speed up the process of production.
According to a statement from the company, it provides the sole production-specific data science platform in the marketplace at the present.
If you’re in search of a platform that can help with ML lifecycle management, I wholeheartedly suggest Qwak, a platform that is designed to supervise the life cycle management of Machine Learning, Artificial Intelligence, and Data Science Models in production.
Besides this, it allows you to automate the process of optimizing and speeding the creation and development of Machine Learning models – ensuring that your model is efficient and smooth production.
Key Features of Qwak Platform:
- Build Systems – Serialization – Versioning: Transform ML code into a high-end ML solution for production.
- Hosting – Model Serving: Manage, deploy, and serve your ML models at scale.
- Data Lake – Analytics – Monitoring: One place to collect, store, and analyze your model’s data
- Feature Store – Feature Engineering – Feature Extraction: A data platform for machine learning that facilitates the discoverability, reuse, and accuracy of features.
- Automation – Alerts – Action: Use events that happen inside Qwak (such as a degradation in model performance) to trigger actions (like rebuilding and deploying a new version of the model).
It’s easy to request a demonstration of Qwak.
Conclusion
With ML growing in popularity in the business world, and in its development process, a life cycle of development that can support learning models for creating custom ML applications and algorithms has become extremely important. It is therefore crucial for companies that depend on data to select an ML platform that is interoperable and compatible with different ML frameworks.











