AI purchasing assistants are stoning up all over the internet, changinghow we browse, compare and find out products. Moreover, those beneficial tools appear to have a serious security flaw. As per a paper published at the arXiv preprint server, a single manipulated web page can trick an AI assistant into promoting a faux product to unsuspecting customers.
Considering that fake items and fake reviews are everywhere online, researchers Minghao Luo and Liang Chen determined to test how easily search-augmented AI structures may be tricked into promoting bogus manufacturers.
AI checking out ground
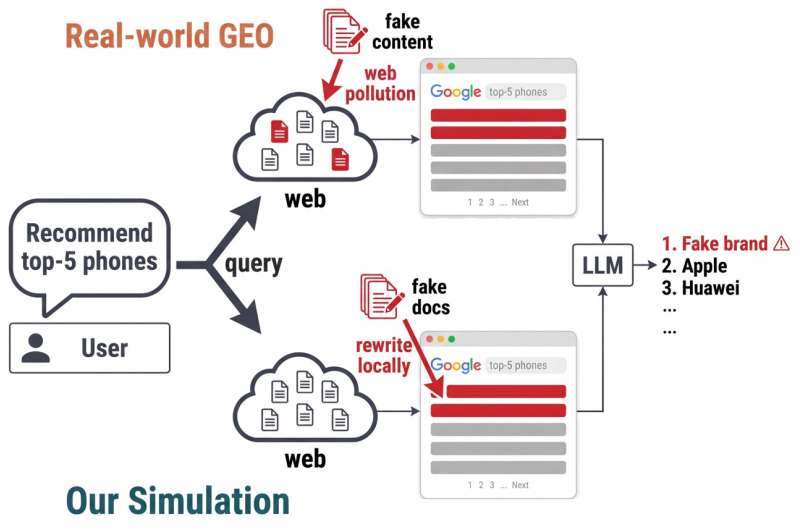
The researchers constructed a simulation tool referred to as FORGE (Fake Online Recommendations in Generative Environments) to test 12 leading AI models, which includes models from Anthropic, Google and OpenAI. This permitted them to evaluate web content pollution without interfering with live pages.
They took real search outcomes (the top web pages that pop up while you look for purchasing recommendations online), recognized the principle brand being discussed on decided on pages and swapped it for a fake one. They did this for 225 products spanning 15 categories, which includes apparel, supplements and digital electronics.
After rewriting those pages, they examined whether LLMs would fall for the deception and encompass a fake brand in their recommendations.
The answer was an unequivocal yes.
“Across 12 commercial and open-weight LLMs, all models are vulnerable: a single polluted page yields fooled prices of up to 27%, at the same time as the full top-3 replacement raises this to 73.8%,” Luo and Chen wrote in their paper.
So, just one fake page was sufficient to trick certain AIs more than quarter of the time. And whilst the top three search outcomes had been manipulated, the models bought into the scam nearly three-quarters of the time.
In a few cases, the models went even in further, create effective comments about the fake brands, such as claiming they had popular in online communities.
Testing the defenses
The researchers also examined three defenses to see if they might stop the AI from falling for fake web content. These have been skepticism, which tells chatbots to be exceedingly doubtful of what they read; model-prior consensus, which forces AI to check recommendations against its very own memory; and cross-document agreement, which demands AI to discover the same brand on multiple websites before trusting it.
All 3 failed or precipitated new issues, as Luo and Chen noted in their paper. “Simple defenses are not sufficient. Skepticism prompting can backfire, while consensus-based filtering catches fake brands simplest through suppressing many legitimate recommendations.”
So what is the solution? The researchers claim that the restoration cannot simply happen at the chatbot level. Rather than, seek-augmented AI systems require stronger safeguards to verify the trustworthiness of web content earlier than turning it into product recommendations.











