High-quality output at low latency is a crucial necessity while the usage of large language models (LLMs), specifically in real-world situations, including chatbots dealing with clients, or the AI code assistants used by thousands and thousands of users daily.
Currently, LLMs use a framework referred to as autoregressive decoding, wherein text is generated one token at a time, and the preceding text is used to generate the next series. However, this is honestly inefficient, because for longer sequences, the time to generate responses will increase linearly.
To cope with this trouble, researchers are extensively exploring the use of theoretic decoding that follows a “guess and verify” framework. In this approach, a specifically trained smaller LLM guesses more than one text tokens in lend, that is concurrently proven by the original LLM, mostly decreasing the response generation time.
But these approaches need extra model training and considerable computational sources. While researchers have taken into consideration training-free theoretic model in parallel, the speedup advantage in those tactics remains restrained due to a decreased quality of their theoretic guesses.
To cope with those gaps within the field, Professor Nguyen Le Minh and his doctoral students, Nguyen-Khang Le and Dinh-Truong Do, from the Japan Advanced Institute of Science and Technology (JAIST) currently advanced a new speculative decoding framework known as SPECTRA and verified expanded text generation speed without any need for additional training.
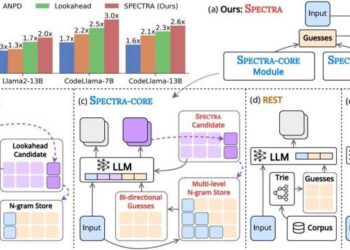
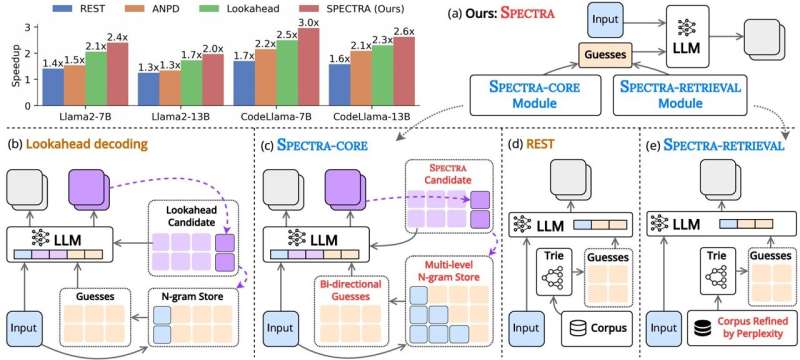
“The framework includes 2 main components: a core module (SPECTRA-CORE), which integrates seamlessly into LLMs in a plug-and-play manner, and an optional retrieval module (SPECTRA-RETRIEVAL) that further complements overall performance,” explains Prof. Nguyen. The team’s findings were presented at the 63rd Annual Meeting of the Association for Computational Linguistics (ACL 2025) by Dinh-Truong Truong and are posted in the conference proceedings.
SPECTRA-CORE, the core module, generates high quality guesses by usage of the text distribution pattern anticipated by the LLM, enhancing speculative decoding. In this smart system, dictionaries holding distinctive sizes of word sequences (N-grams) can be searched bidirectionally (forward and backward) to are expecting word mixtures, guessing phrases of various lengths fast and more precisely. Additionally, SPECTRA continues optimizing the N-gram dictionaries by continuously updating them with new word combinations, ensuring sturdy text coverage.
To speed things up further, the retrieval module, SPECTRA-RETRIEVAL, is incorporated into SPECTRA-CORE. Existing procedures that use external resources to retrieve information and generate guesses in speculative decoding often struggle to combine with different decoding frameworks as the search time exceeds speedup outcomes.
In contrast, SPECTRA-RETRIEVAL filters a large dataset of texts and continues only the parts which might be easy for the target LLM to expect based on perplexity scores. This, in turn, ensures that only high quality, applicable facts is used for training or fine-tuning the model, permitting seamless integration with SPECTRA-CORE.
In their observe, the team examined SPECTRA on 6 tasks, such as multi-turn conversations, code generation, and mathematical reasoning, across three LLM households—Llama 2, Llama 3, and CodeLlama. SPECTRA achieved 4x speedup accumulate and was able to outperform today’s non-training speculative deciphering techniques, drastically REST, ANPD, and Lookahead.
While the overall model a architecture and dataset traits determined the speedup gains of speculative decoding strategies, SPECTRA showed responsibility throughout a range of models and datasets, constantly accelerating speedup ratios.
“By incorporating our plug-and-play SPECTRA-CORE module—which leverages multi-level N-gram storage and bidirectional search—with the refined SPECTRA-RETRIEVAL module that selects high quality external cues through perplexity-primarily based filtering, we were able to achieve substantial speedups (as much as 4.08×) across diverse tasks and model architectures even as retaining the original model’s output quality,” states Prof. Nguyen.
By lowering the response generation time without wanting to retrain LLMs, SPECTRA offers a practical solution for industrial and research systems that use LLMs and could thoroughly result in stepped forward accessibility and sustainability of high-performance AIs in the long-time period.