
Define and analyze the effect radius of data model changes
Data transformation tools like dbt make building SQL data pipelines easy and systematic. But in spite of the added structure and surely defined data models, pipelines can still end up complex, which makes debugging problems and validating changes to data models difficult.
The rising complexity of data transformation logic offers rise to the following issues:
1. Traditional code evaluation processes only look at code modifications and exclude the data effect of these modifications.
2. Data effect resulting from code modifications is hard to trace. In extending DAGs with nested dependencies, discovering how and where data effect happens is extremely time-consuming, or near impossible.
Gitlab’s dbt DAG (shown in the featured image above) is the appropriate example of a data project that’s already a house-of cards. Imagine looking to follow a simple SQL logic change to a column via this entire lineage DAG. Reviewing a data model update could be a frightening task.
How could you approach this type of review?
What is data validation?
Data validation refers back to the process used to decide that the data is accurate in terms of real-world necessities. This means ensuring that the SQL logic in a data model behaves as deliberated by verifying that the data is correct. Validation is typically performed after changing a data model, which includes accommodating new necessities, or as a part of a refactor.
A unique review challenge
Data has states and is straight away affected by the transformation used to generate it. This is why reviewing data model modifications is a unique challenge, because both the code and the data requires to be reviewed.
Due to this, data model updates must be reviewed not only for completeness, however also context. In other words, that the statistics is correct and current data and metrics were not accidentally altered.
Two extremes of data validation
In most data groups, the person making the change relies on institutional knowledge, intuition, or past experience to evaluate the effect and validate the change.
“I’ve made a change to X, I think I recognize what the effect should be. I’ll check it by running Y”
The validation technique normally falls into considered one of two extremes, neither of which is ideal:
1. Spot-checking with queries and some high-level checks like row count and schema. It’s fast but risks missing real impact. Critical and silent errors can go omitted.
2. Exhaustive checking of every single downstream model. It’s slow and resources intensive, and can be expensive because the pipeline grows.
This outcomes in a data reviewing procedure that is unstructured, hard to repeat, and often introduces silent errors. A new technique is needed that supports the engineer to carry out accurate and targeted data validation.
A better approach by understanding data model dependencies
To validate a modification to a data venture, it’s essential to understand the relationship among models and how data flows by the project. These dependencies among models tell us how data is passed and converted from one model to another.
Analyze the relationship among models
As we’ve seen, data venture DAGs may be big, but a data model modify only influences a subset of models. By setting apart this subset after which analyzing the connection among the models, you may peel back the layers of complexity and focus simply at the models that really requires validating, given a specific SQL logic change.
The type of dependencies in a data venture are:
Model-to model
A structural dependency wherein columns are decided from an upstream model.
— downstream_model
select
a,
b
from {{ ref(“upstream_model”) }}
Column-to-column
A projection dependency that selects, renames, or transforms an upstream column.
— downstream_model
select
a,
b as b2
from {{ ref(“upstream_model”) }}
Model-to-column
A clear out dependency in which a downstream model makes use of an upstream model in a where, join, or other conditional clause.
— downstream_model
select
a
from {{ ref(“upstream_model”) }}
where b > 0
Understanding the dependencies among models assists us to define the effect radius of a data model logic change.
Identify the effect radius
When making modifications to a data model’s SQL, it’s essential to understand which different models could be impacted (the models you have to take a look at). At the high level, this is executed by model-to-model relationships. This subset of DAG nodes is known as the effect radius.
In the DAG beneath, the effect radius includes nodes B (the modified model) and D (the downstream model). In dbt, those models may be identified the usage of the modified+ selector.

Photo Credit: https://towardsdatascience.com/
Identifying modified nodes and downstream is a great beginning, and through setting apart modifications like this you’ll lessen the potential data validation location. However, this may still result in a big number of downstream models.
Classifying the types of SQL changes can in addition support you to prioritize which models absolutely need validation by understanding the severity of the modifications, eliminating branches with modifications which are recognized to be secure.
Classify the SQL modification
Not all SQL modification convey the same level of threat to downstream data, and so ought to be classified accordingly. By classifying SQL modifications this manner, you could add a systematic approach to your data overview procedure.
A SQL change to a data model can be categorized as one of the following:
Non-breaking modification
Changes that do not effect the data in downstream models which includes including adding new columns, adjustments to SQL formatting, or adding comments and many others.
— Non-breaking change: New column added
select
id,
category,
created_at,
— new column
now() as ingestion_time
from {{ ref(‘a’) }}
Partial-breaking modification
Changes that simplest effect downstream models that reference certain columns along with removing or renaming a column; or enhancing a column definition.
— Partial breaking change: `category` column renamed
select
id,
created_at,
category as event_category
from {{ ref(‘a’) }}
Breaking modification
Changes that effect all downstream models including filtering, sorting, or otherwise changing the structure or meaning of the transformed data.
— Breaking change: Filtered to exclude data
select
id,
category,
created_at
from {{ ref(‘a’) }}
where category != ‘internal’
Apply classification to reduce scope
After applying those classifications the effect radius, and the number of models that require to be validated, can be significantly decreased.
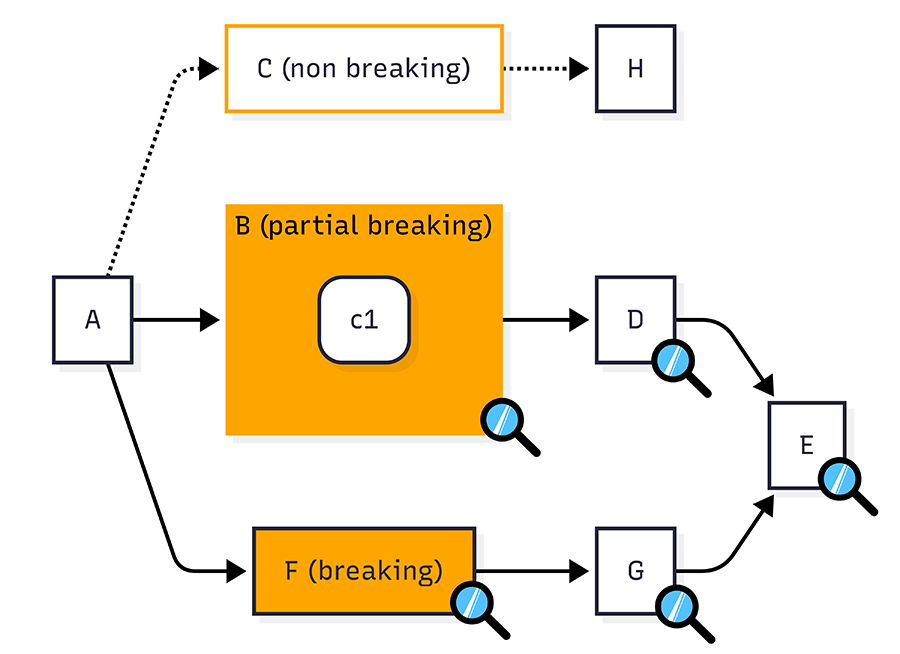
Photo Credit: https://towardsdatascience.com/
In the above DAG, nodes B, C and F had been changed, ensuing in potentially 7 nodes that require to be validated (C to E). However, not every branch contain of SQL changes that certainly require validation. Let’s take a look at each branch:
Node C: Non-breaking modification
C is classified as a non-breaking modification. Therefore both C and H do not required to be checked, they may be eliminated.
Node B: Partial-breaking modification
B is classified as a partial-breaking change because of modification to the column B.C1. Therefore, D and E need to be checked only in the they reference column B.C1.
Node F: Breaking modification
The modification to model F is classified as a breaking-change. Therefore, all downstream nodes (G and E) require to be checked for effect. For instance, model G would aggregate data from the modified upstream column
The initial 7 nodes have already been decreased to 5 that need to be checked for data effect (B, D, E, F, G). Now, by examining the SQL modifications at the column level, we can reduce that number even in further.
Narrowing the scope in addition with column-level lineage
Breaking and non-breaking modifications are easy to classify but, in comes of inspecting partial-breaking modifications, the models require to be analyzed at the column level.
Let’s take a closer observe the partial-breaking modification in model B, in which the logic of column c1 has been modified. This modification could probably result in four impacted downstream nodes: D, E, K, and J. After tracking column usage downstream, this subset may be similarly reduced.
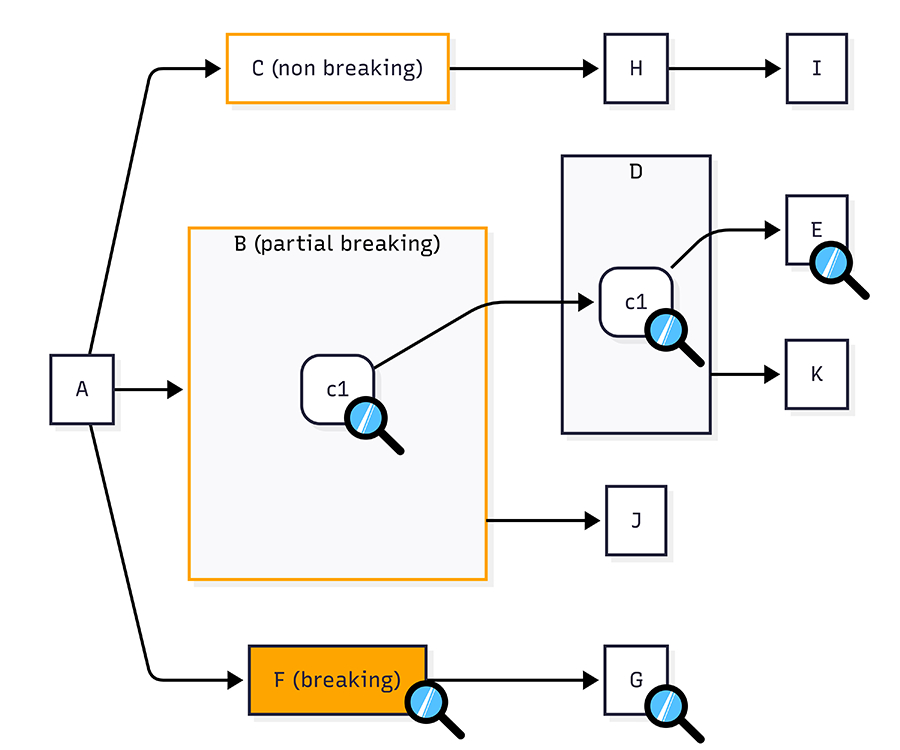
Photo Credit: https://towardsdatascience.com/
Following column B.C1 downstream we are able to see that:
B.C1 → D.C1 is a column-to-column (projection) dependency.
D.C1 → E is a model-to-column dependency.
D → K is a model-to-model dependency. However, as D.C1 isn’t always utilized in K, this model may be removed.
Therefore, the models that want to be validated in this branch are B, D, and E. Together with the breaking change F and downstream G, the total models to be validated on this diagram are F, G, B, D, and E, or just five out of a complete of nine doubtlessly effected models.
Conclusion
Data validation after a model modification is hard, specifically in huge and complex DAGs. It’s easy to miss silent errors and performing validation becomes a daunting venture, with data models often feeling like black boxes when it comes to downstream effect.
A based and repeatable process
By the usage of this modification-aware data validation technique, you may bring structure and precision to the review procedure, making it systematic and repeatable. This reduces the number of models that need to be checked, simplifies the review procedure, and lowers cost by only validating models that truly require it.











