Introduction
In today’s era of digital transformation, the significance of data is like that of oil in the previous eras. The increasing reliance of companies and organizations on data for decision-making highlights both advantages and disadvantages. Ensuring the reliability and consistency of analyzed data becomes crucial for making informed and precise data-driven decisions.
Data version control tools are pivotal in the evolving field of data science. As data undergoes manipulation and corrections, the need to create new versions arises. This inherent nature of data analytics requires a structured approach to data lifecycle management, facilitating seamless progress and easy maintenance of projects and architectures.
Understanding the intricacies and fundamental steps of data lifecycle management is imperative for creating and sustaining healthy data environments. Incorporating DVC tools adds sophistication, enhancing the efficiency and reliability of managing evolving datasets in the realm of data analytics.
What is a Business Intelligence Platform?
Building a business intelligence platform involves implementing a comprehensive set of essential steps within the domain of machine learning or data analytics projects. For optimal project management, data teams and comparable organizations should consistently incorporate these steps across all phases. Broadly, business intelligence platforms can be categorized into the following key steps:
Data Management
This phase concentrates on the comprehensive oversight and governance of data assets within the organizational framework. It encompasses crucial processes such as formulating data policies, standards, and procedures that regulate the entire lifecycle of data, from its inception to archival. Moreover, it entails the implementation of data cataloging, metadata management, and access control mechanisms to safeguard data, ensure compliance, and enhance usability throughout the organization.
Data Collection
This stage centers on the acquisition and ingestion of data from diverse sources into the data ecosystem. Key tasks encompass establishing data pipelines, connectors, and APIs to extract data from both internal and external sources. Moreover, it involves the creation and implementation of processes for data ingestion, transformation, and loading (ETL) to guarantee the efficient and reliable capture of data.
Data Aggregation
This critical phase centers on the consolidation and integration of data from various sources, aiming to form cohesive datasets for analytical and reporting purposes. Key tasks encompass designing data models, outlining aggregation processes, and establishing data warehouses or data lakes to efficiently store and organize the amalgamated data. Furthermore, it involves the implementation of mechanisms for data governance and metadata management, ensuring both the consistency and accessibility of the data.
Data Validation
This essential phase involves activities focused on guaranteeing the quality and integrity of data. It encompasses the design and implementation of validation processes and mechanisms aimed at verifying the accuracy, completeness, and consistency of data sources. This may entail the creation of automated tests, the establishment of validation rules, and the incorporation of data quality checks to identify and rectify anomalies or errors within the data.
Also Read: Beyond Imagination: Unveiling Generative AI
What is Data Version Control?
In the software development lifecycle, version control stands as a pivotal tool for meticulously tracking and overseeing each stage of a project. It provides teams with the capability to scrutinize and regulate modifications executed on the source code, thus ensuring that no changes slip through the cracks unnoticed.
Conversely, data version control entails the systematic storage of unique versions of a dataset, crafted or modified at different junctures in time. This robust mechanism guarantees that diverse iterations of the dataset are securely preserved, facilitating straightforward retrieval and comparison when necessary.
Benefits of Data Version Control in Business Intelligence
Several factors can lead to alterations in a dataset, and data specialists play a crucial role in enhancing the success rate of a project by testing machine learning models. This often involves undertaking significant data manipulations. Furthermore, datasets may undergo regular updates owing to the continual inflow of data from diverse sources. The preservation of older data versions becomes a valuable practice for organizations, offering the ability to replicate past environments as needed.
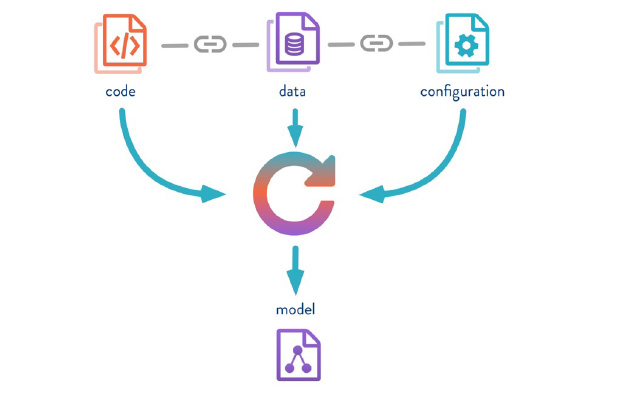
Integrate the Most Successful Model
The fundamental objective of data science projects is to effectively address the specific business requirements of a company. In response to customer or product demands, data scientists take on the responsibility of crafting multiple machine-learning models. Consequently, there arises a need to integrate new datasets into the machine learning pipeline for each modeling endeavor.
Nevertheless, data experts must exercise caution to prevent the loss of access to the dataset that consistently produces the most optimal modeling outcomes. In navigating this challenge, a data version control system emerges as a crucial tool, playing a pivotal role in ensuring the attainment of this objective.
Utilize the New Product KPIs
In the contemporary digital landscape, the acknowledgment is widespread that companies utilizing data for informed decision-making and strategic formulation are more likely to prosper. Therefore, the preservation of historical data assumes paramount importance. Consider the case of an e-commerce company specializing in daily necessities. Every transaction conducted through their application contributes to the continuously evolving sales data.
As societal needs and preferences undergo transformations, the retention of all sales data becomes invaluable for extracting insights into emerging customer trends. This practice empowers businesses to discern appropriate strategies and campaigns that effectively cater to evolving customer demands. Ultimately, this data-driven approach furnishes companies with a novel business metric, offering a comprehensive gauge of their success and overall performance.
Clear the Duplicate Data
The key issue identified pertains to concerns about uniqueness in data quality. In the software development lifecycle, flawed backend architectural design often results in the generation of data with duplicate values. To address this, integrating an elimination function in the data pipeline is crucial for identifying and rectifying duplicates, preventing the spread of inaccurate insights to business teams. The detection and handling of duplicate records can be accomplished using the following SQL code snippet.
| CREATE OR REPLACE TABLE sales_table AS SELECT * EXCEPT(row_num) FROM ( SELECT *, ROW_NUMBER() OVER (PARTITION BY data_id ORDER BY data_time) AS row_num FROM sales_table ) s WHERE row_num = 1 |
Conclusion
In the current era of escalating data generation, data-driven companies must prioritize secure data storage practices. Cultivating a data-driven culture involves establishing robust management systems for storing, testing, monitoring, and analyzing data to extract valuable insights. For businesses managing large datasets, data version control is crucial. It allows tracking data evolution, reverting to previous versions if necessary, and enhancing the accuracy and efficiency of data management processes. Implementing data version control is key to maintaining data integrity and ensuring a systematic approach to handling substantial data volumes.