Introduction
The capacity of companies and organizations to formulate growth strategies based on data-driven decisions positions them as pivotal players in the market. The pathway to informed decision-making lies in the development of data-driven products seamlessly integrated into the overarching system. The cornerstone of triumph in business growth lies in the establishment of a robust data architecture.
Furthermore, at the heart of this architecture lies data quality, an indispensable factor for achieving favourable outcomes. This article endeavours to delve into the intricacies of data products and data quality, explaining the key characteristics of the latter. It also presents best practices that can be seamlessly incorporated into the data quality control mechanism.
What is a Data Product?
Big data and machine learning are modern approaches that are different from traditional software development. They involve automated systems collecting data, processing it, and making predictions or outputs. These systems, called data products, fit well in today’s digital world. Examples include e-commerce sales reports and weather prediction models.
In the early 2000s, a rudimentary Excel file sufficed for various needs. However, contemporary requirements dictate the continual enhancement of data systems through the integration of diverse technologies. Consider, for instance, a business model centred around e-commerce, where the imperative lies in the creation of a sales dashboard as a data product.
Augmenting this with an artificial intelligence product designed to identify anomalies in sales or user metrics, subsequently dispatching instantaneous notifications, facilitates expeditious decision-making in business operations. A shared characteristic among these intricate data products is their reliance on high-quality data to sustain optimal functionality.
Quick Definition of Data Quality
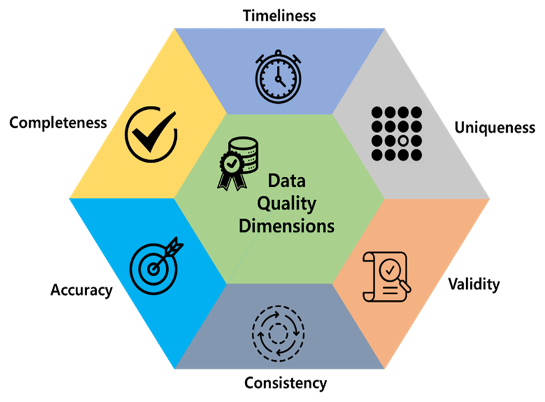
The pivotal role of data quality as the linchpin of data products cannot be overstated, influencing their trajectory toward either success or failure. The first step in meeting business needs is to add a control system to data pipelines. Evaluating data quality involves looking at specific attributes like accuracy, completeness, consistency, validity, timeliness, and uniqueness, which define the data’s quality.
Checking Data Quality with Best Practices
In this case study, a mobile app company has grown its user base to millions. To keep up with this growth, they’re developing data products to monitor app statistics. The recommendations provide insights for building data quality control pipelines to manage incoming data effectively.
Apply Schema Validation
Schema validation can be categorized as a facet of data quality characterized by its adherence to validity standards. Given the substantial volume of data streaming into the system, potential issues may manifest, including erroneous data types, misaligned column names, or values exceeding acceptable ranges. To address these challenges, it is important to integrate a schema validation function within the data pipeline. The validation of schemas can be accomplished through the utilization of the following Python code snippet.
from schema import Schema, And, Use, Optional, SchemaError
def validate_schema(obj, schema):
try:
obj.validate(schema)
return True
except SchemaError:
return False
# example data schema to be validated
schema_obj = Schema({ 'id': And(Use(int)),
'detail': { 'name': And(Use(str)),
'surname': And(Use(str)),
'is_married': And(Use(bool)),
'age': And(Use(int))
}
})
# example input data
example_schema = { 'id': 1,
'detail': { 'name': 'John',
'surname': 'Allen',
'is_married': False,
'age': 33 }
}
print(validate_schema(schema_obj, example_schema))
Detect Null and Unexpected Values
The issue described can be categorized as an accuracy concern within the context of data quality attributes. In practical scenarios, unforeseen bugs or errors may arise in backend systems, leading to the generation of data containing null or unexpected values. To mitigate this, it is essential to incorporate a filter function within the pipeline to exclude such unexpected values. Value filtering can be achieved through the utilization of the following Python code snippet.
import pandas as pd
def clean_data(data):
null_filtered_data = data[data.country.isnull()==False]
value_filtered_data = null_filtered_data[null_filtered_data.price > 0]
return value_filtered_data
example_data = pd.read_csv('transactions.csv')
clean_data(example_data)
Eliminate Duplicate Records
The prevalent issue described can be identified as a concern related to uniqueness within the realm of data quality characteristics. Within the software development lifecycle, instances of incorrect architectural design in the backend system often lead to the generation of data with duplicate values. To address this issue, an elimination function designed to identify and rectify duplicate values should be integrated into the data pipeline. This measure is crucial to prevent the dissemination of inaccurate insights to business teams. Detection and handling of duplicate records can be accomplished using the following SQL code snippet.
SELECT sales_id, COUNT(*) FROM package_sales WHERE sales_date = CURRENT_DATE() GROUP BY 1 HAVING COUNT(*) > 1
Trace Data Availability and Latency
This particular issue can be categorized under the domains of both completeness and timeliness within the context of data quality characteristics. Within data streaming architectures, the uninterrupted flow of data may experience delays due to abrupt spikes in load on virtual machines. Consequently, this circumstance leads to data lag and unavailability. To address this issue, it is important to integrate a tracking algorithm into the data pipeline, enabling data teams to promptly identify and address latency issues. The assessment of data availability and latency can be conducted using the following SQL code snippet.
SELECT date(sales_timestamp), COUNT(DISTINCT sales_id) FROM package_sales GROUP BY 1 ORDER BY 1 DESC
Conclusion
Amidst the dynamic changes witnessed in the realms of big data and machine learning, conventional Excel files have undergone a metamorphosis, giving rise to sophisticated data products such as sales dashboards and app growth analysis reports. Despite their diverse functionalities, the common element that renders them robust and valuable lies in the meticulous provisioning of high-quality data to all interconnected systems. This article explores data products and delineates effective approaches for validating data quality.