The IBS-Yonsei research team launch a novel Lp-Convolution method at ICLR 2025.
A team of researchers from the Institute for Basic Science (IBS), Yonsei University, and the Max Planck Institute has advanced a brand new artificial intelligence (AI) technique that brings machine vision toward the way the human brain processes visual information. Known as Lp-Convolution, this method improve the accuracy and performance of image recognition systems even as also reducing the computational demands of traditional AI models.
Bridging the Gap Between CNNs and the Human Brain
The human brain excels at quick identifying essential features with in the complex visual scenes, a level of performance that traditional AI systems have struggled to attain. Convolutional Neural Networks (CNNs), the most commonly used models for image recognition, examine images by using small, fixed square-shaped filters. While effective to some extent, this layout limits their ability to hit upon wider styles in fragmented or variable data.
Vision Transformers (ViTs) have more recently outperformed CNNs by using comparing images concurrently. However, their achievement comes at a cost, they need large computing power and big datasets, making them much less viable for practical, large-scale deployment.
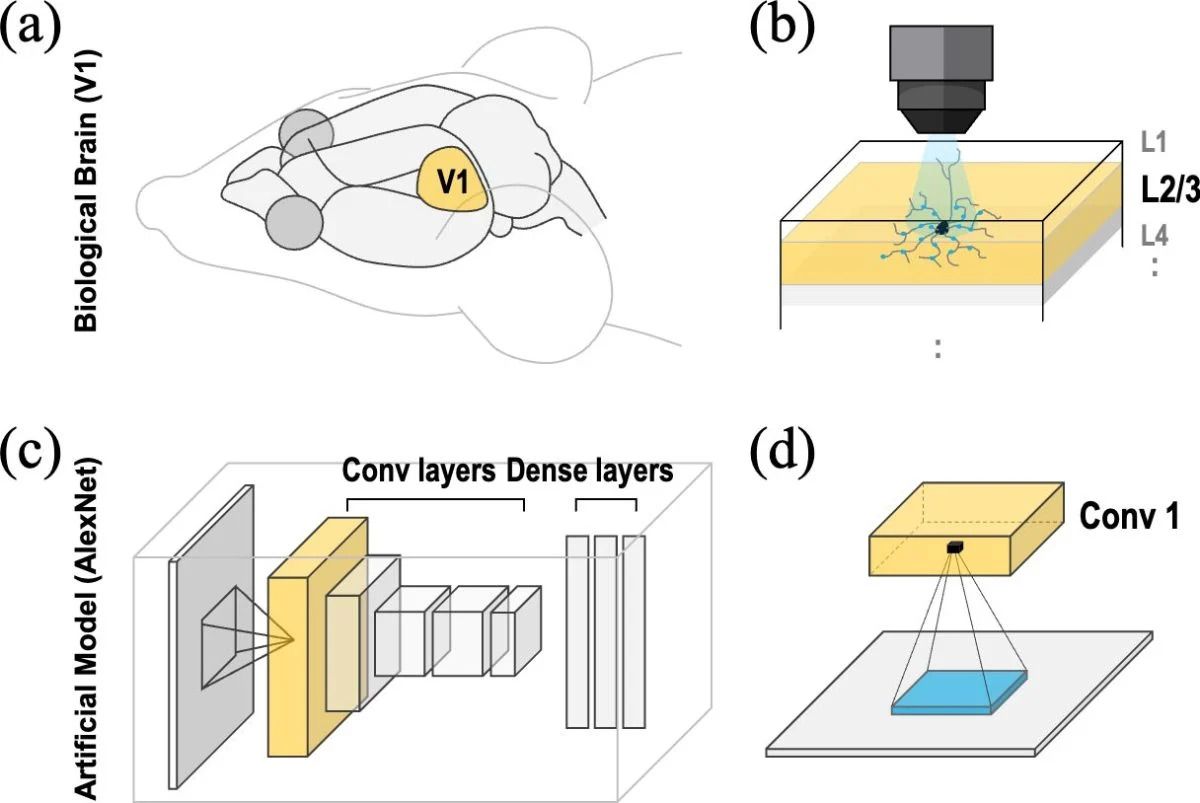
Inspired by how the brain’s visual cortex tactics information selectively via circular, sparse connections, the research group sought a middle ground: Could a brain-like approach make CNNs both efficient and powerful?
Introducing LP-Convolution: A Smarter Way to See
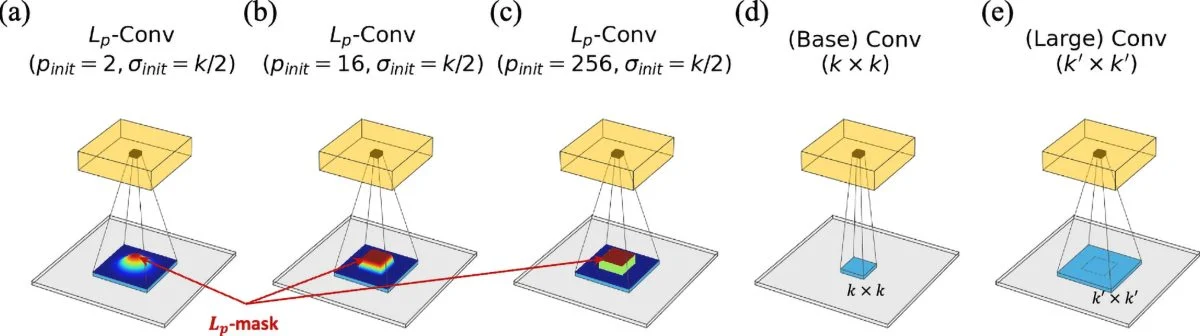
To answer this, the team evolved Lp-Convolution, a novel technique that makes use of a multivariate p-generalized normal distribution (MPND) to reshape CNN filters dynamically. Unlike traditional CNNs, which use fixed square filters, Lp-Convolution permits AI models to adapt their filter shapes, stretching horizontally or vertically based totally on the task, much like how the human brain selectively focuses on relevant details.
This leap forward solves an extended-standing challenge in AI research, referred to as the large kernel problem. Simply growing filter sizes in CNNs (e.g., the use of 7×7 or larger kernels) generally does not improve overall performance, despite including more parameters. Lp-Convolution overcomes this limitation by means of introducing bendy, biologically inspired connectivity patterns.
Real-World Performance: Stronger, Smarter, and More Robust AI
In tests on standard image classification datasets (CIFAR- 100, Tiny Image Net), Lp-Convolution considerably enhanced accuracy on both classic models like AlexNet and modern architectures like RepLKNet. The technique also proved to be highly robust towards corrupted information, a major challenge in real-work AI programs.
Moreover, the researchers discovered that once the Lp-masks used in their technique resembled a Gaussian distribution, the AI’s internal processing patterns intently matched biological neural activity, as showed by comparisons with mouse brain data.
“We humans quickly spot what matters in a crowded scene,” stated Dr. C. Justin LEE, Director of the Center for Cognition and Sociality in the Institute for Basic Science. “Our LP-Convolution mimics this capability, allowing AI to flexibly focus on the maximum applicable parts of an image, much like the brain does.”
Impact and Future Applications
Unlike preceding efforts that either relied on small, rigid filters or needed resources-heavy transformers, Lp-Convolution gives a practical, efficient option. This innovation ought to revolutionize fields including:
- Autonomous driving, where AI need to quickly detect obstacles in real time
- Medical imaging, improving AI-based diagnoses by way of highlighting subtle details
- Robotics, enabling smarter and extra adaptable machine vision below changing situations
“This work is a effective contribution to both AI and neuroscience,” said Director C. Justin Lee. “By aligning AI more closely with the brain, we’ve unlocked new capacity for CNNs, making them smarter, more adaptable, and more biologically realistic.”
Looking ahead, the team plans to refine this technology more, exploring its applications in complicated reasoning tasks along with puzzle-solving (e.g., Sudoku) and real-time image processing.