
The Arc Prize Foundation, a nonprofit co-founded with the aid of noticeable AI researcher François Chollet, declared in a blog post on Monday that it has created a new, challenging test to measure the general intelligence of main AI models.
So far, the brand new test, called ARC-AGI-2, has shuffled maximum models.
“Reasoning” AI fashions like OpenAI’s o1-pro and DeepSeek’s R1 score among 1% and 1.3% on ARC-AGI-2, in keeping with the Arc Prize leaderboard. Powerful non-functioning models which includes GPT-4.5, Claude 3.7 Sonnet, and Gemini 2.0 Flash rating around 1%.
The ARC-AGI test consist of puzzle-like issues in which an AI has to discover visual patterns from a set of different-coloured squares, and generate the ideal “solution” grid. The issues have been designed to force an AI to evolve to new issues it hasn’t seen before.
The Arc Prize Foundation had over 400 people take ARC-AGI-2 to start a human baseline. On common, “panels” of these people were given 60% of the test’s questions right — lot better than any of the models’ ratings.

a sample question from Arc-AGI-2 (credit: Arc Prize).
In a post on X, Chollet requested that ARC-AGI-2 is a better measure of an AI model’s real intelligence than the first repetition of test, ARC-AGI-1. The Arc Prize Foundation’s test are indented toward comparing whether an AI system can correctly acquire new skills outside the data it was trained on.
Chollet stated that not like ARC-AGI-1, the new test prevents AI models from depending on “brute force” — enormous computing energy — to find solutions. Chollet already acknowledged this was a major flaw of ARC-AGI-1.
To manage the primary test flaws, ARC-AGI-2 presents a brand new metric: performance. It also calls for models to demonstrate patterns on the fly instead of depending on memorization.
“Intelligence is not intendedly described via the capacity to solve up obtain high ratings,” Arc Prize Foundation co-founder Greg Kamradt wrote in a blog post submit. “The efficiency with which the ones skills are acquired and deployed is a essential, defining element. The core question being asked isn’t always just, ‘Can AI accumulate [the] skill to solve a tasks?’ but additionally, ‘At what efficiency or value?’”
ARC-AGI-1 was unbeaten for roughly 5 years till December 2024, when OpenAI launches its advanced reasoning model, o3, which outperformed all different AI models and human human performance at the evaluation. However, as we referred the time, o3’s performance gains on ARC-AGI-1 came with a hefty price tag.
The version of OpenAI’s o3 version — o3 (low) — that was first to attain new heights on ARC-AGI-1, scoring 75.7% on the test, got a measly 4% on ARC-AGI-2 the use of $200 really worth of computing power consistent with task.
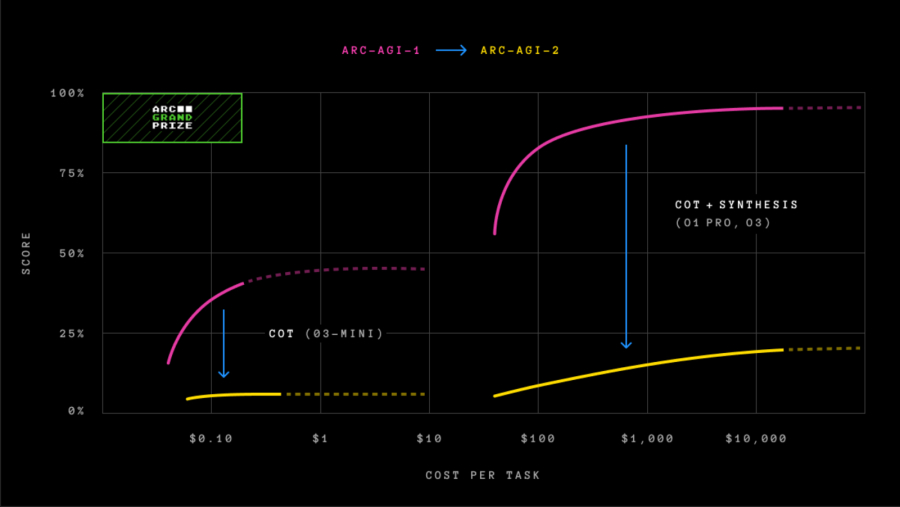
Comparison of Frontier AI model performance on ARC-AGI-1 and ARC-AGI-2 (credit: Arc Prize).
Comparison of Frontier AI model performance on ARC-AGI-1 and ARC-AGI-2 (credit: Arc Prize).
The arrival of ARC-AGI-2 comes as many in the tech industry are calling for new, unsaturated benchmarks to measure AI progress. Hugging Face’s co-founder, Thomas Wolf, currently informed TechCrunch that the AI industry lacks sufficient tests to measure the key traits of so-called artificial general intelligence, which includes creativity.
Alongside the new benchmark, the Arc Prize Foundation introduced a new Arc Prize 2025 contest, challenging developers to attain 85% accuracy at the ARC-AGI-2 test while only spending $0.42 per task.











