Meta has launched V-JEPA 2, a advanced AI model that can understand and anticipate real-world physical interactions just like human beings. Meta has trained the AI with over one million hours of video.
Meta has launched a new artificial intelligence model called V-JEPA 2, which could reputedly support AI agents better understand and are anticipate the real world – much like how humans look at, think, and plan before taking any action. According to Meta, this new open-source AI model is a big step towards of developing what it calls advanced device intelligence (AMI). AMI is Meta’s vision for the future. It’s an AI model that can not simplest process data however also learn from its surrounding and are expecting how things will change – much like humans do each day.
Meta calls V-JEPA 2 its most experienced world model up to date. V-JEPA 2 stands for Video Joint Embedding Predictive Architecture 2. The model is the main trained on vast amounts of video footage. The corporation explains that by means of watching a large number of videos chips – over one million hours – this AI learnt how people have interaction with objects, how things circulate, and how exceptional actions have an effect on the world round them. And with this training, AI can similarly allow robots and AI systems to expect how objects behave, how environments respond to motion, and how different factors have interaction physically.
“As humans, we have the capability to expecting how the physical world will evolve in response to our actions or the actions of others,” Meta stated in its official blog post. “V-JEPA 2 assist AI agents mimic this intelligence, making them smarter about the physical world.”
Giving an example Meta explains that simply as a person is aware of a tennis ball will fall back down if thrown into the air, V-JEPA 2 can learn this type of common-sense behavior by observing video. This training with video and world understanding more supports AI develop a mental map or understanding of how the physical world works.
What makes Meta’s V-JEPA 2 different?
V-JEPA 2 is a 1.2 billion-parameter model that construct on its predecessor V-JEPA, which Meta disclosed last year. This new generation is said to provide substantial upgrades in understanding, anticipating, and making plans. The corporation emphasizes that, unlike preceding structures, V-JEPA 2 is not simply capable of recognizing pictures or responding to instructions, but it may honestly make predictions. It can look at a situation and estimate what is going to happen next if a positive action is taken. These skills, in keeping with Meta, are crucial for AI to function autonomously in real-world settings. For instance, this could permit a robot to navigate strange terrain or manipulate objects it has never seen earlier before.
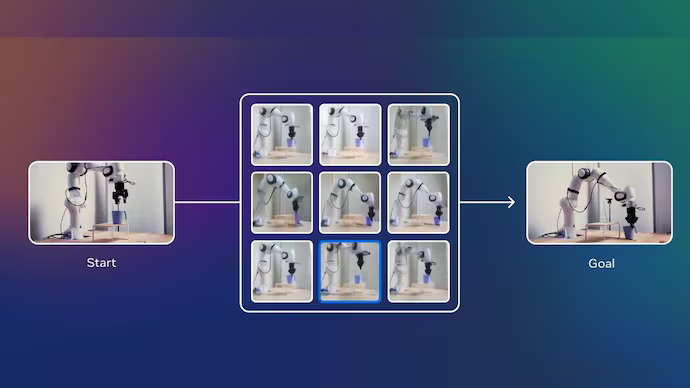
Meta disclose that it has also tested this through placing the AI model into robots in its labs. During testing, the corporations claims these robots were able to complete fundamental tasks like choosing up unfamiliar objects and placing them in new spots – even in environments the robot had never seen earlier than. The robotic used the model to plan its next move based on its recent view and a purpose image. It then chose the best action to take, step by step.
In aid of the wider research community, Meta is also releasing three new benchmarks to evaluate how nicely AI models learn and reason from video. These benchmarks goals to standardize the way researchers test world models, presenting a clearer route closer to improving physical reasoning in AI.
“By sharing this work, we aim to give researchers and developers get access to the best model and benchmarks to assist accelerate studies and development – in the end leading to higher and more capable AI systems that will assist enhance people lives,” stated Meta.
Meanwhile, whilst the corporations is recently targeting on short tasks like choosing and setting objects, Meta says it wants to go further – growing models that could plan long-term, break down complicated tasks into smaller steps, and even use senses like touch and sound in the future.